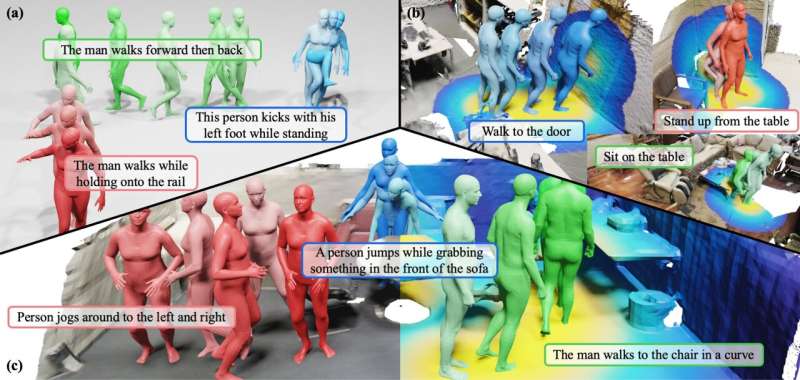
在过去的几年里,能够自主生成各种类型内容的基于机器学习的模型变得越来越先进。这些框架为电影制作和汇编数据集以训练机器人算法开辟了新的可能性。
虽然一些现有的模型可以根据文本描述生成逼真的或艺术的图像,但迄今为止,开发可以根据人类指令生成移动人物视频的人工智能更具挑战性。在服务器arXiv上预发表并在IEEE/CVF计算机视觉与模式识别2024年会议上发表的一篇论文中,北京理工大学、BIGAI和北京大学的研究人员介绍了一个有前途的新框架,可以有效地解决这一任务。
“我们之前工作的早期实验,HUMANIZE,表明一个两阶段的框架可以通过将任务分解为场景基础和条件运动生成来增强3D场景中语言引导的人体运动生成,”该论文的合著者Yixin Zhu告诉Tech Xplore。
“机器人领域的一些工作也证明了可视性对模型泛化能力的积极影响,这激励我们将场景可视性作为这项复杂任务的中间表征。”
朱和他的同事们介绍的新框架建立在他们几年前介绍的一个生成模型的基础上,这个模型被称为HUMANIZE。研究人员着手提高该模型在新问题上的泛化能力,例如,在学会有效地生成“躺到床上”的动作后,对“躺到地板上”的提示做出真实的动作。
该论文的合著者黄思远解释说:“我们的方法分两个阶段展开:用于功能图预测的功能扩散模型(ADM)和用于从描述和预生成的功能生成人体运动的功能扩散模型(AMDM)。”
“通过利用从人体骨骼关节和场景表面之间的距离场导出的功能图,我们的模型有效地将3D场景接地和该任务中固有的条件运动生成联系起来。”
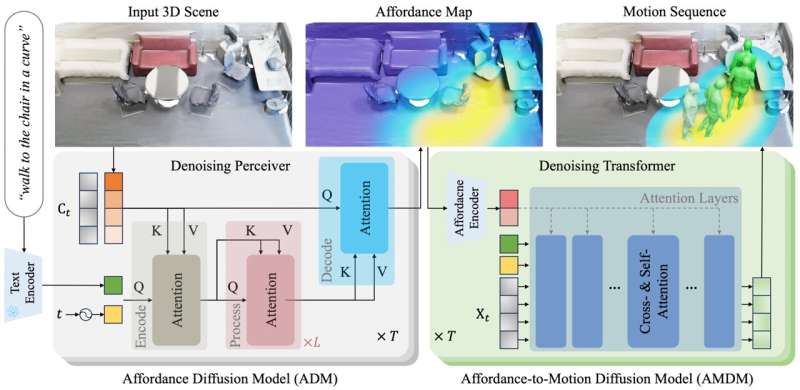
该团队的新框架与之前引入的语言引导的人类运动生成方法相比,有许多显著的优势。首先,它所依赖的表示清楚地描绘了与用户描述/提示相关的区域。这提高了它的3D接地能力,使它能够在有限的训练数据下创造出令人信服的动作。
该论文的合著者魏亮说:“我们模型使用的地图也提供了对场景和运动之间几何相互作用的深刻理解,有助于它在不同场景几何上的推广。”“我们工作的关键贡献在于利用明确的场景可视性表示来促进3D场景中语言引导的人体运动生成。”
Zhu和他的同事的这项研究展示了整合场景可视性和表征的条件运动生成模型的潜力。该团队希望他们的模型及其基本方法能够激发生成式人工智能研究界的创新。
他们开发的新模型很快就会进一步完善,并应用于各种现实问题。例如,它可以使用人工智能制作逼真的动画电影,或者为机器人应用程序生成逼真的合成训练数据。
“我们未来的研究将集中在通过改进人机交互数据的收集和注释策略来解决数据短缺问题,”朱补充说。“我们还将提高我们的扩散模型的推理效率,以增强其实际适用性。”
更多信息:Zan Wang et al ., Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance, arXiv(2024)。DOI: 10.48550/ arXiv .2403.18036
©2024 Science X Network
引用:一个新的 从语言PROM生成人体动作的框架 pts(2024年4月23日)检索自https://techxplore.com/news/2024-04-f 这个文档 作品受版权保护。除为私人学习或研究目的而进行的任何公平交易外,未经书面许可,不得转载任何部分。的有限公司 内容仅供参考之用。